 推广
推广
2020年12月7日-10日,由腾讯游戏学院举办的第四届腾讯游戏开发者大会(Tencent Game Developers Conference,简称TGDC)在线上举行。维塔士技术总监Andy Fong以《在高寒处保持温暖——Switch游戏优化经验分享》为主题发表演讲。

以下为演讲整理内容:
我先来介绍一下自己,本人是在2007年加入维塔士上海工作室,在游戏开发编程领域方面已经有超过13年的从业经验。近年我参与了《最终幻想12:黄道年代》、《黑色洛城》、《星链:阿特拉斯之战》、《生化奇兵:合集》、《幽浮2:典藏合集》等的Switch游戏开发。
在介绍任天堂Switch方面的优化之前,先介绍一下我自己感受到的任天堂开发这个Switch平台的理念还有重点。
我认为它是着重于创新功能,包括把移动平台跟主机合并在一个游戏机里面,方便玩家可以用同一款游戏在移动跟主机平台都可以体验。
实际上主机跟移动平台在操作上,是没有太大区别,很容易就可以适应在两个不同的情况下去玩游戏,存档也是可以在两者之间共享的。
在手柄方面,Switch投入了新的HD Rumble,就是让振动更有触感,也可以通过红外线检测玩家的手部移动还有形状。

在多人游戏方面,Switch允许玩家用两个手柄在同一台主机去进行多人游戏,也可以在多台的Switch主机之间连线去进行多人游戏。
这吸引到很多喜欢本地多人游戏的玩家,但相对来说在这个年代,并没有投入最高性能的硬件到主机上面。
如果把PC、Xbox One或其他的主机游戏移植到Switch的话,内存使用是需要有所降低的。
在游戏性能方面,如果要保持在30 FPS这样的性能,那也需要做CPU或GPU的优化。
一般来说,对于移植其他平台游戏到Switch平台的话,需要在预生产的阶段进行优化计划,然后到后期的时候实现计划。
这里展示了两张图,实际上就是同一款游戏在两个主机平台的截图,这是《生化奇兵合集》在Switch平台上面的游戏,左边这一张是Switch平台,右边是Xbox One的。

展示这两张图目的是想说,我们公司在尝试去稳定Switch平台能够保持30帧这样的目标,希望能够保持这个游戏能有跟原来游戏一样的画质还有游戏性。
我们争取保持这两点,其他游戏可能会采用别的方法,比方说牺牲画质或者是游戏性这样去达到性能目标,但其实有些客户,是不容许掉帧的,同时他们也要求画质跟游戏性能够达到跟其他的游戏平台一样的水平。

面对这样的要求,我们需要更多的做代码、算法的优化,以及更多支持多核心芯用到这个平台机器的功能,尽量去优化比较次要的数据从而去达到这个性能目标。
接下来,我会针对过去项目的经验介绍我们采用的优化策略,这一页就是我这个讲座的大致概览,首先我会介绍内存优化这一方面的调查、优化,就是当一款游戏进行内存优化到一定水平之后,我们会展开CPU跟GPU方面的优化工作。
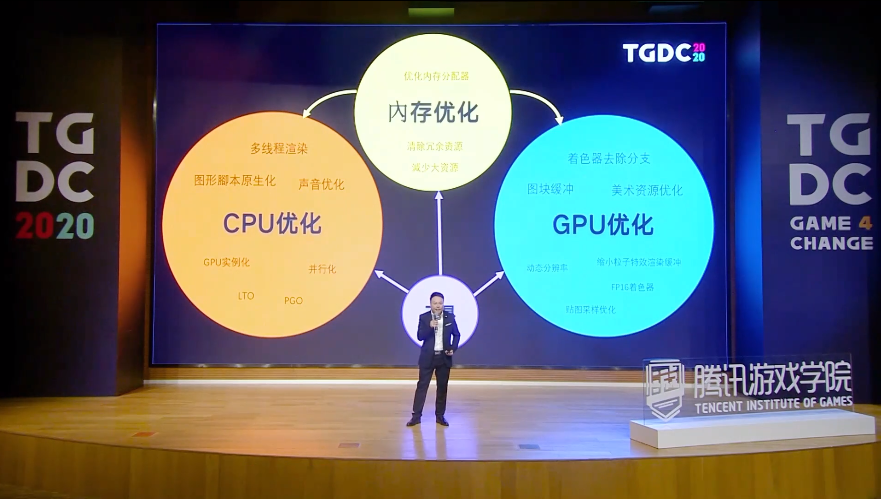
先介绍CPU的,再介绍GPU的优化,最后我会谈谈对内存、CPU、 GPU这三方面都有帮助的工具。
减少内存分配开销,清除冗余资源
首先我们开始去讲内存优化,刚才也提到了如果我们从PC Xbox One、PS4游戏平台尝试把游戏移植到Switch的话,很容易会触碰到Switch的内存上限,一旦超过这个上限之后游戏就很容易会崩溃,如果我们要顺利开发的话,肯定是需要进行内存优化。
接下来我会介绍分析、优化的工作,这里展示不同统计的工具,上面是日志报告的工具,下面是屏幕统计的工具,屏幕统计工具实是通过底层内存的分配器去收集到各个模块使用到的内存。
然后在屏幕上展示日志报告,其实也是收集这样的信息,但这是通过QA测试或者是一些自动测试Autotest。就是在测试完之后,把报告产生出来,事后可以让程序员去分析。

还有一些专用工具包括引擎或是SDK方面都会提供专用的内存分析工具,可以去查找内存泄露,除了上面的屏幕统计、日志报告之外,我们会用这样的工具,发现更深入的问题,然后去查找哪里使用了内存。
通过这些工具,一般来说我们都能够知道整个游戏运行的时候,内存使用的分布,然后就开始从大块的使用比较多内存的模块开始,制定开发优化的策略,一步步把内存优化下来。
接下来我会介绍方法,首先第一个介绍的是优化内存分配器的方法。实际上,内存分配器是所有游戏一般都会使用的系统,它是帮助我们从底层去分配内存给不同的系统使用。
内存分配器会有自己的开销,引擎在管理内存的时候,也有额外的开销。两者是有重复的,所以我们是更推荐于使用底层虚拟内存分配接口去配合引擎方面或者是第三方内存页面分配器方面的功能。

两者结合去控制这方面的开销,同时在VRAM的管理方面,我们可以推荐CPU跟GPU能够共享内存,可以达到动态控制VRAM的分配,这样可以在需要的时候提高VRAM的使用,也就是虚拟内存的使用。
如果CPU的内存需要更多的话,可以动态地去平衡在VRAM的处理方面,我们推荐用一开始分配比较大的内存池,避免后面如果需要分配内存池的话,会因为碎片的问题分配不出来了。
接下来是关于我们对VRAM使用什么样的缓冲,我们是不太推荐使用环缓冲还有双缓冲这样的结构,我们更推荐使用类似于DX的WriteDiscard或者是WriteNoOverwrite。
WriteDiscard果分配一块大的内存,可以把过去的内存丢弃了,然后重新分配一块新的WriteNoOverwrite,在一个大块的内存里面一块一块小块的去分配,这样可以减少分配内存的开销,加快速度,清除冗余资源。
如果从其他平台转移去Switch平台的话,实际上因为其他平台内存比较足够,所以会有冗余的资源,包括不必要的立体声的音频、渲染缓冲,预加载的关卡。

在Switch上面,我们推荐会用更激进的一些streaming,就是加载关卡的策略,会更严谨去选取真正需要的关卡去加载,如果是非必要的话,我们尽量争取去把它去掉或者是减少它,达到一个内存平衡。
常驻贴图,这里说到就是很可能其他的平台会选择把UI贴图或者是低层的mipmap贴图,里面比较底层的贴图会保留在内存里面一直常驻。在Switch上面,很多时候是不允许的,我们会选择性去加载贴图,只保留当前需要用的贴图。

关于着色器的二进制文件,在我们用着色器的编译器去编译之后,不同的着色器有可能产生一样的二进制文件。通过调查,我们会争取找到重复的二进制文件,确保它的唯一性。
还有就是,我们在打包着色器二进制文件的时候,也希望能够尽量在游戏开始的时候就已经把二进制文件打包在一起,然后一起加载。
因为如果我们是分布的,在不同情况,加载二进制文件也有机会产生更多的额外开销。
当我们清除掉冗余的数据之后,剩下的都是真正游戏需要用的。但这些我们也是争取需要减少它们,包括贴图,一般都是游戏里面占用比较大内存的部分,我们会采用ASTC的压缩格式。
这个格式,可以看到,最右边的这张贴图就是ASTC相对于其他格式。实际上它能够比较好的去保护原来贴图的画质细节。实际上也可以允许去调整不同的参数,去对这个贴图进行压缩,在保护画质的同时,可以达到比较好的一个压缩率。


对于mipmap贴图的不同等,我们会调整最高的mipmap等级,因为实际上在Switch上面,屏幕分辨率已经有所降低了,并不需要时刻地保持最高分辨率的mipmap,我们可以限制最高mipmap的使用。
后边就是其他的内存块,包括渲染缓冲,实际上我们可以检查GBuffer延迟渲染里面使用的GBuffer,就是一个大的缓冲,它的布局是怎么样的,很可能里面是有些效果是不必要的,可以把渲染缓冲给节省掉。
动画我们也进行压缩,实际上很多引擎都支持动画压缩,它可以使用更激进的压缩方法,让这个动画的数据更加小一点,模型我们会检查不同的LOD,有可能有一些LOD,实际上是不需要的,我们就直接去把它去掉了。
我们也碰到很多关卡使用内存过大的问题,其中一个方法我们会拆分大的关卡,再拆分成两个、三个、更小的关卡。只有当你处于特定关卡的时候,才加载那个关卡,这样也可以大大节省使用的内存。
用多线程渲染提升GPU、CPU工作效率
上面就大致讲完了几个我们会做内存优化的方向,一般来说,做过这些优化之后,游戏是能够跑起来了,但是有可能还没达到30帧,我们会在GPU跟CPU方面进行优化工作。

实际上两方面的工作都需要,在33.3毫秒里面完成面对不同游戏的差异,有时候CPU的工作会多一点、有时候GPU会多一点。
接下来我会先分享一些,CPU分析还有优化的方法,这里就列出了CPU性能的分析工具。
首先我们会选择采用引擎专用的工具,包括双引擎4里面的Stat命令,这里展示的就是UE4里面的Stat的命令。
列出的参数实际上是罗列了CPU里面各个模块使用的时间,我们也会用第三方工具比方说Frame Pro,它是沿着时间线把不同的函数给罗列出来,不同函数使用时间也能够很清晰的看出来。
实际上Switch平台,也有提供自己的CPU研究工具,但这个是受到NDA保护,如果有任天堂开发者帐号,可以去了解这方面的工具。
说到CPU的问题,实际上很多时候会联想到draw call,这样会产生一个问题就是渲染线程上面投入的时间太长,接下来我会介绍优化的方法,在过去开发的经验里面,我们会使用到多线程渲染,之前我们开发过开放世界的游戏项目。
因为开放世界,看到很宽阔的场景,所以draw call很高,在那个时候我们也分析了其他的核心,实际上其他核心的使用率是不高的。所以我们考虑采用多线程渲染的方法,首先就是先考虑单线程的情况下。
实际上CPU那边是负责去产生命令缓冲,就是产生命令投入到一个命令缓冲里面,最后会提交给GPU去进行渲染,改变到多线程会怎么样呢?
其实就是,我们会研究过Switch平台的图形接口,实际上是能接受多线程渲染的,我们会给各个线程产生独立的命令缓冲。
难点是在于Setup,图片里面有提到Setup,就是设置的部分,在我们渲染每一个draw之前,我们都需要通过Setup的步骤。当我们把这些draw分派给所有不同线程的时候,我们要确保每个线程、每个draw call都能有一个正确的设置。
所以你可以看到,我们分摊到多个线程的时候实际上多了一些Setup,就是设置的工作,最后我们需要确保所有缓冲能够顺序的提交到GPU里面。
在单线程的情况是一个渲染缓冲,依次提交给GPU,虽然我们多线程有很多的渲染缓冲,我们还是要确保它们按顺序的排列,最后依次再提交到GPU那边。

这里再提到的一些例子,实际上从单线程去到多线程其中一个很大的难点就是拆分队列,在单线程里面实际上在Setup就是设置这个部分,它可以做到局部的设置,并不需要全部的参数都刷一遍,可以局部的去刷多线程的时候,因为它拆分了所有的队列之后,有机会它会需要去刷更多的参数。
我们可以看看左边的例子,可以看到在它渲染第二个draw的时候,如果把draw分摊给另外一个线程去工作,在这个draw之前是需要一个复Full Setup的。
因为实际上,它没有准备好,还需要做设置参数的设定,再看看右边例子,实际上在第二个、第三个draw之前,有一个叫Partial Setup就是局部的设定,如果我们把第二个、第三个Draw,把它分派到另外一个线程,是需要做全局的设定。
因为很可能这些如果只做一个部分设定的话,它很可能还是会漏掉一些设定,这是其中一个困难,我们在开发这个方法的时候,实际上碰到很多问题就是很多状态都没有设置对,就产生了很多显示的问题,后来设置对了。
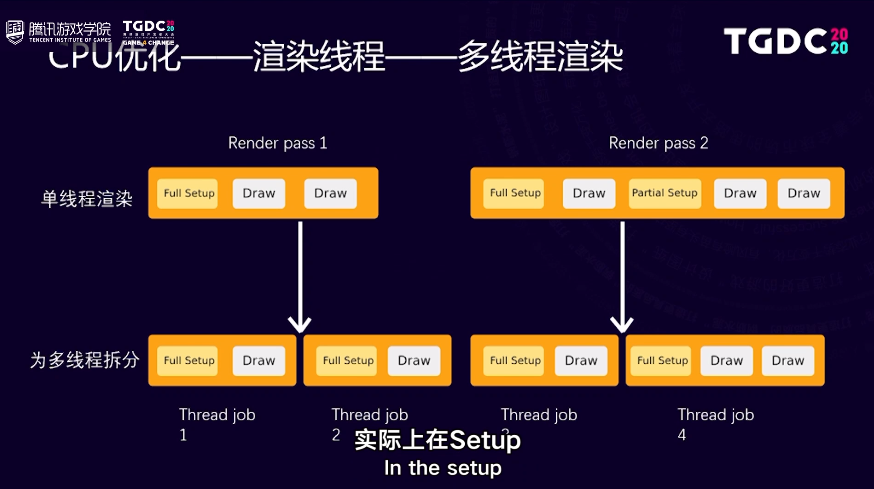
但我们发现这个设置本身,也带来很多额外的开销,所以后面我们就采用了一个方法,就是我们尝试争取用不同的渲染步骤去拆分任务,去到多线程那边,减少设置。
当我们完成了多线程渲染之后,实际上在准备命令缓冲的时间就从20毫秒减到6毫秒,实际上也是一个很不错的提升。后边就进入到另外一个优化,叫图形脚本的原生化。
实际上图形脚本,更多是在主线程那边去执行的,现在越来越多引擎会使用图形脚本,进行游戏逻辑,包括UE4的蓝图,这些脚本很容易上手,游戏策划也可以去使用,但如果是重度使用的话,很可能会对主线程的性能产生压力,因为它调用的函数会比较多,调用栈站也比较深。

一般来说,我们会采用原生化的方法去把脚本转换成C++代码,也有两种方法,一种是部分原生化,一个是深度原生化。那部分原生化的话,就是我们会自己去检查,哪一些脚本的性能损耗是比较高的,去选择性的把局部脚本转换成C++代码。
深度原生化的话就是,我们会更多的去实现工具,把图形脚本转换成C++代码,这个会达到更高的提升,当然也会投入更多时间去开发这样的工具,在过去的项目,我们曾经有经验能达到10%到20%这样的提升。
后边是关于声音的优化。实际上声音在现在新时代的游戏都是很重要的一个方面。

我们会先采用第三方,如果是用第三方去播放声音的话,会用第三方的声音库提供的专用工具进行性能检查。然后在Switch上面使用压缩方法,就是OPUS还有ADPCM。
那OPUSpus这个格式的话,是有很好的压缩率,解压缩速度也很快,但是有一个问题是,声道比较有限,如果有一些现在的声音声道比较多的话,会转移采用ADPCM去播放它们。
其实还有另外一些问题,就是关于DSP音效的播放,这些效果实际上是需要采用CPU去进行运算,我们推荐把这些效果烘焙到声道上面,让它去直接播放,节省运算效率,保护关键声音的实例,把次要、低优先值的声音实例给去掉,或者是把它的频率给降低,就是让它不要那么频繁地去播放,也可以节省运算时间。
对于距离远的3D声音,可以考虑把它放到虚部,放成一个虚部声音的话,可以减少运算,只有当它靠近比较明显的时候才开始去计算它们。
好了,上面提到的就是大致我们比较很常用的CPU优化,实际上这里还有更多的CPU优化,如果以后有机会,我们可以再多交流这方面,接下来我会介绍GPU方面的性能分析、优化方法。
GPU性能的话,一般会跟着色器的效率有关,也会跟每个渲染命令所填充的像素会有一定关系,对于Switch的主机模式以及掌机模式,我们一般会推荐使用1080p的分辨率、掌机会使用720p。这也是考虑到在这两个模式底下的GPU的性能,这样去定义的话,确保能在不同的模式都达到30帧的帧率。

接下来谈一下分析的工具,一般来说,我们会采用SDK提供的API去获取GPU里面不同步骤的渲染时间。把它罗列在屏幕上面,就像这个截图上面一样。
也会采用SDK提供的专门工具研究GPU上的问题,如果有任天堂开发者帐号的话可以多了解这个工具。
我们对这两方面收集起来的数据进行对比,确认最终GPU问题在哪里。有时候我们也会采用个别工具,把某些效果关掉、打开,这样对比耗用的时间,可以确认某些效果所耗用的时间。
接下来是优化,一般来说,我们会考虑去除分支,对于着色器的程序,会去除一些分支。实际上分支语句无论是对于CPU或者GPU,都是一些难点。因为没有办法去判断程序的流向,着色器的分支会被平坦化。
意思就是说,分支的两边都会执行,最后会选择其中一个结果,但是如果它们工作量不平衡的话,也会影响到在GPU上面执行的并行性。

所以我们尽量争取去移除掉分支页面,我们展示了一些方法,首先第一个是替换写法,使用特殊语句,比方说叫saturate还有lerp语句,可以很好地去替代原来的分支语句。
也可以使用一种条件编译,把不同分支的代码组织成不同的着色器二进制文件,然后在C++那边去进行判断。当你可以能够判断每一个draw call实际上只用到某一个分支代码的时候,你就可以这样去做,在C++那边就已经判断出来使用某个特定的着色器二进制文件,执行二进制文件避免你每一个数都需要去判断,做这个分支的语句,对性能会有相对比较好的提升。
下一个是一个叫图块缓冲的优化方法,这个是属于Tegra GPU的功能,GPU可以接受一些绘制的请求收集起来,再把渲染缓冲划分成很多的图块,一个一个图块播放渲染的请求。

这样的好处就是,当你在一个图块上面去渲染的时候,实际上它在访问一些帧缓冲命中cache的机会会大大提高。当你能够去从cache里面获得数据的时候,能够大大地加快你的访问速度。
这个使用场景是什么呢?就是当你有很多大面积的粒子实际上这个图展示的粒子效果,这些粒子效果都需要去访问帧缓冲,一般来说,我们尝试过把PS2的游戏移植到Switch。实际上PS2上面VRAM的带宽还是比较高的,去到Switch上面需要优化图块缓冲是不错的选择。
在一些情况下,我们会达到五毫秒的提高,但需要注意的是这里面有收集渲染命令,还有播放的步骤。就是当我们渲染的一些单元使用比较大量的顶点属性,还有频繁地切换这些属性的话,建议还是不要太多去使用,因为可能会在收集跟播放会增加开销。
接下来是关于美术数据,一般来说我们在所有GPU手段都没有太大的效果,包括动态分辨率、图形缓冲、图块缓冲,这些都没有太多的帮助的情况下。

我们会考虑对美术资源进行优化,这里有一张截图是《幽浮2》的基地截图。实际上它展示了很多不同的小房间,在最开始的时候,所有的小房间都是充满了很高精度的细节。
实际上我们发现当镜头拉得比较远的时候,并不需要对所有房间都能够提供这么高的细节的视觉。我们就对每个房间都创建了LOD的模型,实际上就是不同层值、不同精度的模型,可以在拉远的时候采用相对精度比较低的模型。
实质上在Switch的屏幕上面是不太能看出区别,除了这个模型之外,就是关于粒子效果,我们也是有游戏会采用粒子的LOD去渲染粒子,也得到不错的优化。
其他方面还有就是对于比较不明显的地方,可以选择不去做投影或者是降低密度,都去节省GPU的开销。
接下来想讲帮助优化的工具,当游戏跑到某一个位置突然严重的掉帧,会在屏幕展示警告,像warning frame-drop这样的显示很容易就被QA或者是开发人员给检测出来,马上就开展调查,了解为什么会掉帧了,也会去专门给某些特定敌人或者是技巧去做功能,去处罚敌人。

对于模型的话,我们会采用第三方软件,比方Simplygon还有Houdini,这样去制作低模的LOD模型替换高模模型进行自动测试。
我们很多时候都会让编译器去自动去跑游戏,然后收集内存、性能的信息,这样可以让开发人员调查问题时,节省QA的测试成本。
这些分享,我想表达的核心目标是希望能够在保护游戏的画质、游戏性的情形下,能够保证Switch游戏到稳定帧数,加强玩家体验。

包括三方面,首先就是内存需要优化到位,包括分配器,要时刻关注它额外的开销,对于冗余数据,会检查是不是有渲染缓冲可以节省,常驻的贴图是不是可以变成非常驻。对于大的数据资源,包括贴图,采用ASTC压缩技术。对于CPU方面的优化,就是多线程渲染,可以帮助减轻渲染线程的压力,在主线程对图形脚本进行原生化,把它转换成C++代码。
声音方面,我们推荐使用OPUS压缩格式,对于GPU的话对着色器会进行一个去除分支操作,比方说用lerp语句取代原来的分支语句。对于图块、图块缓冲可以有效优化粒子效果,特别是大面积的粒子效果。
到最后我们会对美术数据进行选择性优化,包括采用LOD或者是关闭投影效果,达到降低GPU消耗这样的目的。我们也会采用工具,包括检测掉帧的工具、自动测试的工具,尽量给开发人员提供有用信息,加快优化工作。
Q&A
从技术层面来说跨平台适配的难点在哪里?如何应对?
实际上跨平台适配来说,我们会遇到很多可能,第一方面是底层系统的适配,包括内存I/OIO 输入输出,还有渲染器的适应。因为不同平台对底层接口也是不一样,我们要进行适配,就是参考原来用到哪些功能,然后在新平台需要怎么去实现这些功能。
第二点,就是优化,我们讲了很多优化,不同平台的性能水平是不一样的,很可能在移植另外一个平台需要进行优化,其实就是处理的方法,我们提早去优化的策略,提早去对原来的游戏进行分析。
哪些地方会成为优化的难点,进行计划,怎么去达到优化的效果,还有就是,一些平台独有的要求,不同平台对游戏发布是有独有要求的,比方说有一些平台对多人游戏的安全性是有独有的要求。
这样的话,我们需要越早去安排工作,对服务器端或者是客户端,都要进行调整,这样去能够符合到专门的要求。
在做原生化的时候会遇到哪一些困难?
首先是工具的适应性,一般来说工具并不能完全百分百对不同类型的脚本都进行适应。需要一步一步去调整,包括脚本、工具方面。可以说是磨合过程,慢慢就可以全面的把脚本转化成另外一种类型。
但转化正确性的问题,就是我们每当转变图形脚本到C++做了原生化,都需要去验证脚本逻辑的正确性,因为它是按时间去触发某些事件的,比如在转移到C++上面去执行,可能时间点就不一样了,也会产生一些问题,我们需要去适应这些问题。
还有第三点,就是脚本方面会更改的问题,有时候我们会并行开发不停地在更改脚本,每次更改脚本之后,可能原生化又产生问题。我们又要去验证一遍,确保它都能够很好的原生化变成C++的代码。
如果我们从其他平台移植到Switch的话,还会需要做哪些方面的优化呢?
我能想到的第一点就是一些极端情况,虽然我们会实现比较通用的优化,在大部分的情况,游戏都能够在30帧上面去运行,但还是会有不少的极端情况,就是特别多的特效、场景、物件。
实际上,针对各种各样的极端情况,我们需要更深度地研究个别的case,制定更激进的优化策略。这些情况都是需要更多的精力去优化,才能有可能达到性能的目标。
还有一点就是加载时间,实际上加载时间就不单指在Switch了,在各个平台都会需要有一定的优化。因为我们都在跟时间竞争,所有的玩家都希望能够瞬间就进入到游戏里面。
这方面的话,一般来说我们要分析加载的过程里面会加载了哪些数据。也要看有没有调整的方法。有时候,我们调整加载的顺序,也可能会有提高或者把一些资源变成常驻的。
还有就是选择性的去优化部分数据来提高加载速度,还有就是安装包、下载包,一般来说发行商方面会希望追求能够减少的。因为Switch上面有卡带,那我用哪一个尺寸的卡带呢?
还有就是如果要下载的话,要下载多少数据到Switch的机器上,其实也是对各种包进行分析,有时候像在游戏包里面一些视频,可以选择考虑改变或者降低分辨率,这些都有机会掌握它的大小,控制安装包或者下载包的大小。

下载「陀螺科技」APP
获取前沿深度元宇宙讯息





